.webp)
.webp)



EdgeAI comes in 2, 4, and 8-GPU builds. Run open frontier models for development or production. Your IP and customer data never leave the box. No API bills. Train and fine-tune your own models — sovereign compute on your own floor.
8× RTX 5090. A local inference box for teams shipping with open models. Develop, serve, fine-tune, and protect the work that should never leave your floor. Read more.






4× RTX 5090. Built for larger open models like Kimi, MiniMax, and GLM. No API bills. Low latency. Private data.
.webp)
.webp)
.webp)
.webp)


2× RTX 5090. Enough for Llama, Qwen, and DeepSeek with quantization. Run OpenClaw, Hermes Agent, or your own LangChain stack locally. Read more.






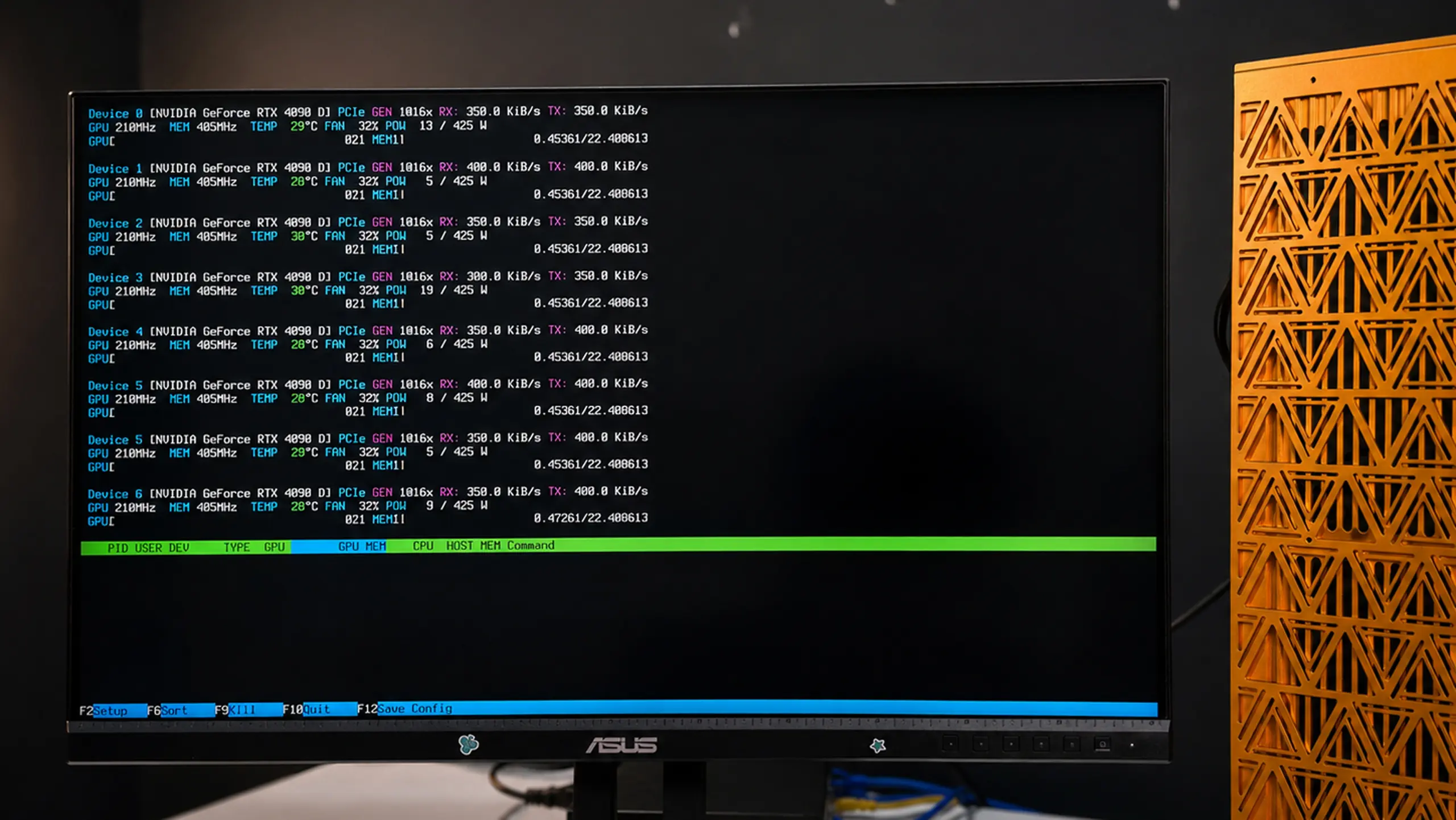
Every EdgeAI is tested before shipping. Boot WinPE from USB to verify GPUs at the hardware layer, or run Ubuntu with NVIDIA drivers, nvidia-smi, and nvtop.
Silicon runs hot. EdgeAI is CNC-milled from solid aluminum to move heat and resist bending. The triangular cutouts keep stiffness high without carrying dead weight.




-1 LAN 2.5Gb


